AUTORI

Marco Pesarini
Partner @Bip xTech

Giuseppe D’Agostino
Senior Cloud & Data
Architect @Bip xTech

Luca Natali
Senior Cloud & Data
Architect @Bip xTech

Martino Ongaro
Cloud & Data Engineer
@Bip xTech
Tra i pilastri fondanti alla base delle organizzazioni guidate dai dati – data driven organization – a cui tutte le aziende moderne puntano da dieci anni a questa parte, vi è sempre stato il data lake, un grande archivio informatico dove trasferire tutti i dati aziendali, così come sono, senza troppe trasformazioni, per rendere i dati accessibili a tutti. Per democratizzare l’accesso al dato, come si usa dire.
In questo disegno, al dato si dà un valore intrinseco, quasi naturale, per cui ci si aspetta che, con le nuove tecnologie, dal data engineering alla data science, chiunque acceda al dato ne possa trarre una evidenza, un significato, senza bisogno di avere troppa esperienza del contesto da cui il dato deriva.
Lavorando in questi anni su progettualità in quest’ambito abbiamo però riscontrato che il modello soffre di alcune complicazioni di fondo. Questa spinta ad estrarre il dato grezzo dal dominio di nascita, per elaborarlo in piattaforme centralizzate, ha creato due problemi, che saranno familiari a chiunque abbia praticato un po’ il campo: la difficoltà nella ricerca e nella interpretazione del dato, fatte da chi non ne conosce la provenienza, e la cronica bassa qualità del dato disponibile, perché chi estrae e mette a disposizione il dato non è poi responsabilizzato sull’utilizzo.
Per affrontare questi problemi le aziende si stanno attrezzando sempre di più con articolate strutture di data governance, che definiscono responsabilità, processi e ruoli per garantire la chiarezza del dato e preservarne la qualità. La soluzione a questi problemi non può però essere solo organizzativa, serve anche un aiuto tecnico che semplifichi un po’ la sostanza del modello.
In questo senso molto interessante è l’intuizione di Zhamak Dehghani nel suo articolo “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”[1] che propone un nuovo modo di gestire il dato aziendale, prevedendo di riportare l’analisi dello stesso nel dominio di origine. Dove il dato nasce. Secondo questo approccio, sono gli esperti del dominio da cui il dato proviene ad essere responsabili della interpretazione e della qualità. La responsabilità sui dati del cliente ricade nel dominio del CRM, quella sui dati di bilancio nel sistema gestionale, quella su quelli di vendita nel dominio dell’e.commerce, e così via. È facile comprendere come in questo disegno i problemi di interpretazione e qualità del dato diminuiscano sostanzialmente, stante l’esperienza che nel dominio vi è sul dato. La gestione e interpretazione del dato diventano esperte.
La parte principale dell’intuizione sul data mesh sta però nella soluzione proposta per evitare una ricaduta nel vecchio mondo dei silos informativi, in cui il dato era mascherato e perso nei vari domini di origine. Ai domini è data la responsabilità di creare prodotti dati – data product – che siano strumenti di esposizione e interpretazione del dato da pubblicare all’intera azienda. Questi prodotti sono resi disponibili nel mercato informativo interno e possono essere remunerati, ossia dotati di budget per la loro crescita, a seconda di quanto siano effettivamente utilizzati o sottoscritti da altri utenti.
Si crea un libero mercato – e questa è la sfida degli strumenti a supporto del data mesh – in cui tutti gli utenti possono trovare e fruire di tutti i prodotti dati aziendali, e dalla naturale competizione per il budget tra i domini deriva una benefica spinta alla esposizione e condivisione del dato.
I dati sono sì riportati sotto la responsabilità del dominio, ma in un mercato dove i singoli domini sono motivati a esporli e renderli comprensibili e di qualità. Mettendo l’esperienza di dominio alla base della valorizzazione del dato.
Come si compone un data mesh
Il data mesh fonda le sue basi teoriche nel modello architetturale del Domain-Driven Design, secondo il quale lo sviluppo software deve essere strettamente legato ai domini di business all’interno di un’organizzazione. Nel DDD ogni dominio organizzativo è rappresentabile da un domain model, ossia una combinazione di dati, comportamenti caratteristici e logiche di business che guidano lo sviluppo del software di dominio. Lo scopo principale del DDD è realizzare software pragmatico, consistente e scalabile, scomponendo l’architettura in servizi all’interno dei singoli domini e puntando sulla loro riusabilità nella composizione dei differenti prodotti software a supporto dell’azienda. La prima implementazione del DDD nell’ambito dell’enterprise software è stata la revisione delle applicazioni monolitiche verso le architetture basate sui microservizi: ogni microservizio è circoscritto in un dominio ed è responsabile di soddisfare i requisiti di una specifica operazione erogando una funzione applicativa a tutti i prodotti che ne fanno richiesta.
Il data mesh applica il DDD alle architetture in ambito dati. Nascono i data product che permettono di accedere ai dati del dominio attraverso delle funzioni elementari che espongono interfacce puntuali e mettono a disposizione dati grezzi, dati pre-processati o dati elaborati secondo determinati requisiti. Come i microservizi sono componenti software che espongono funzionalità applicative elementari, i data product sono componenti software che espongono dati e funzionalità analitiche elementari nel dominio. I data product hanno l’obiettivo di suddividere le funzioni analitiche del dominio in prodotti elementari e riusabili, come i microservizi suddividono le funzioni applicative.
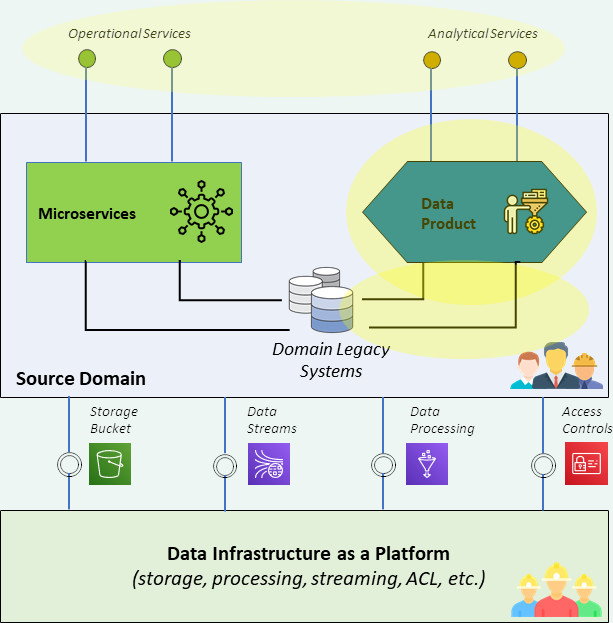
Come già per le architetture a microservizi, anche nel data mesh, il nuovo modello disaggregato necessita di una serie di regole e di strumenti per mantenere un buon governo dell’insieme.
In primo luogo, i data product devono rispettare alcune caratteristiche, che sono funzionali a creare il mercato libero di cui si parlava. Indipendentemente da come venga creata la specifica interfaccia di accesso ai dati – è possibile dare accesso tramite una API, tramite una vista su un database, o tramite un sistema di virtualizzazione – o dal tipo di dato che venga messo a disposizione, i data product devono rispettare le regole identificate nell’acronimo DATSIS secondo il quale il prodotto deve essere:
- Discoverable – i consumatori devono essere autonomi nella ricerca e nell’individuazione dei data product realizzati dai differenti domini
- Addressable – i data product devono essere identificati con un nome univoco seguendo una nomenclatura comune
- Trustworthy – i data product devono essere realizzati dai domini che detengono i dati e devono mettere a disposizione dati di qualità
- Self-describing – i consumatori devono poter usare i dati esposti dai data product senza doverne chiedere il significato agli esperti di dominio
- Integrated – i data product devono essere realizzati seguendo degli standard condivisi per essere facilmente integrati nella architettura e riusati per realizzare altri data product
- Secure – i data product devono essere sicuri by design e l’accesso al dato deve essere regolamentato a livello centrale tramite politiche standard di sicurezza
Solo rispettando queste regole si possono creare data product che consentano un disegno di mesh efficace e affidabile.
Passando poi agli strumenti, due sono i fattori essenziali per costruire un data mesh funzionante: la data infratructure as a platform e l’ecosystem governance.
Demandando lo sviluppo dei data product ai singoli domini applicativi l’organizzazione rischia di veder aumentare il tasso di eterogeneità delle tecnologie in uso e di rendere la strategia sourcing molto complessa. Nell’implementazione di un data mesh è quindi importante che un’azienda si doti di una piattaforma infrastrutturale comune – la data infrastructure as a platform – che metta a disposizione di tutti i domini i mattoni tecnici per la creazione e la fruizione dei data product: storage, pipeline, database, funzioni di calcolo, giusto per citarne alcuni. Qualunque dominio voglia costituire i propri data product dovrà far uso di questi mattoni, accedendo alla data infrastructure as a platform in modalità self-serve, e questo permetterà una standardizzazione dello sviluppo dei data product e l’introduzione di un linguaggio comune tra i vari domini. Le piattaforme cloud PaaS sono una opzione interessante per costituire questa infrastruttura comune su cui costruire i data product garantendo costo controllato e rapidità di implementazione.
La creazione di data product in modalità distribuita rischia poi di aumentare il tasso di duplicazione e la complessità di accesso al dato, facendo perdere gli obiettivi di qualità e di responsabilità sui dati da cui il paradigma del data mesh è partito. Per questo è molto importante che l’azienda si doti di strumenti di ecosystem governance, su cui fornire visibilità e comprensibilità ai data product; su questi strumenti ogni data product potrà essere registrato e di conseguenza ricercabile e riusabile secondo specifiche politiche di autenticazione e autorizzazione.
Prospettiva tecnica
Introdotti i concetti di data product, data infratrutcure as a platform e ecosystem governance, entriamo in una prospettiva più tecnica per dare tangibilità a questa introduzione.
In prima luogo i data product non sono altro che insiemi di componenti software, spesso già note alle aziende, per il caricamento, la conservazione, l’elaborazione, e l’analisi del dato. Prendiamo ad esempio un data product che sia uno strumento per la produzione di un report per esaminare i mattoni che possono costituire il data product.
Come detto, i mattoni alla base del data product provengono dalla data infrastructure as a plaftorm. Qui troviamo tecnologie consolidate tra cui storage per oggetti e code di eventi, un layer di elaborazione sia batch che streaming e strumenti per il consumo dei dati per reporting, BI, ML ed AI. Strumenti, in somma, già largamente conosciuti ed adottati.
Prendendo l’esempio del data product che produce un report, i mattoni costitutivi potrebbero essere uno storage che conserva i file da cui estrarre di dati, un engine Spark per l’estrazione e l’elaborazione, un database dove appoggiare i dati elaborati, una vista per l’analisi e visualizzazione del report e un API per fornire i risultati.
Per la realizzazione del data product la data infrastructure as a platform ha anche il compito di fornire gli strumenti per permettere l’orchestrazione delle componenti e la collaborazione tra gli utenti. In essa troviamo quindi le tecnologie di orchestration (come ad esempio Airflow, Dagster, DataFactory), che permettono di coordinare l’esecuzione delle elaborazioni, e i più recenti strumenti di data modeling, per agevolare la collaborazione in fase di sviluppo fra ingegneri e analisti (ad esempio Dremio, e Data Build Tool).
Nel caso del nostro data product, questi strumenti permettono da un lato l’esecuzione ordinata dei comandi e delle funzioni che generano il report e, dall’altro, una più efficace collaborazione fra il data engineer che usa Spark per gestire i dati sullo storage, il modellista che struttura il modello dati sul database, l’analista che lo utilizza per l’esplorazione e lo sviluppatore che distribuisce gli esiti sotto forma di API.
A questo punto, il data product è pronto per essere consumato anche all’esterno del dominio, e qui entrano in gioco gli strumenti di ecosystem governance adatti a gestire il catalogo e la distribuzione dei data product. Fra i principali strumenti per l’organizzazione cross-domain troviamo le tecnologie di federazione, di catalogazione dei data product, e le tecnologie di data discovery, che redono i prodotti visibili e fruibili agli utenti finali (come ad esempio Amundsen, Metacat, Atlas). Con l’inserimento di questi strumenti, gli utenti di un altro dominio posso ricercare e accedere al data product, sfruttando le funzionalità di ricerca semantica o scorrendo il catalogo centrale dell’azienda.
A completamento della piattaforma di ecosystem governance vi sono poi le funzioni a presidio della compliance, della qualità dei dati, del controllo e monitoraggio degli accessi. Il nuovo Data Steward nell’ipotesi di un ecosistema basato sul cloud di AWS sfrutterà gli alert automatici di AWS Comprehend per identificare violazioni della privacy, Glue DataBrew per controllare la qualità dell’output del nuovo data product, Lake Formation per controllarne i permessi interni ed esterni al dominio e CloudTrail per monitorarne accessi ed uso.
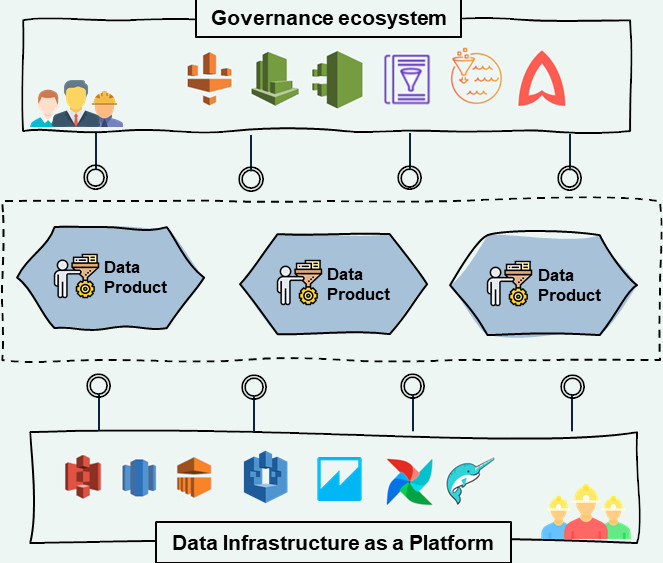
Prospettiva organizzativa
Un ultimo aspetto importante da considerare, nella valutazione del paradigma del data mesh è l’adattamento organizzativo che la sua introduzione potrebbe richiedere. Da questa prospettiva la transizione è più facile per chi ha già adottato modelli organizzativi agili con chapter competenziali di dominio e squad di sviluppo.
Il principio di fornitura del dato come “prodotto” vede la nascita in questo modello di nuove figure quali i Data Product Owner – affini agli storici Product Owner – all’interno dei singoli domini; figure responsabili del ciclo di vita dei data product (pianificazione, monitoraggio, ecc.) e dell’esecuzione della strategia di dato del dominio.
Altre figure professionali già presenti nelle attuali organizzazioni vengono distribuite nei domini: la decentralizzazione della responsabilità sul dato, e del processamento dello stesso da parte del dominio di competenza, fa sì che figure come i Data Engineer e Data Architect siano spostate all’interno dei singoli domini. Nascono i Data Engineer del dominio “cliente” nel mondo del CRM, per fare un esempio, come in passato sono nati gli sviluppatori di microservizi verticali sullo stesso dominio.
In questa organizzazione distribuita sui domini, resta però centralizzata la funzione responsabile delle politiche di governance (che segue tra l’altro l’interoperabilità, la sicurezza, la compliance, ecc.). Una entità organizzativa centrale che assicuri l’applicazione delle politiche in tutti i domini e che si compone di figure tecniche a livello enterprise (ad esempio Enterprise Data Architect, Enterprise IT Architect, ecc.), di rappresentanti dei domini e di esperti di sicurezza e compliance.
L’altra, e ultima, funzione che resta centralizzata in questo modello è quella a presidio della data infrastructure as a platform che gestisce la piattaforma infrastrutturale per tutti i domini con profili di ingegneria di piattaforma ed esercizio.
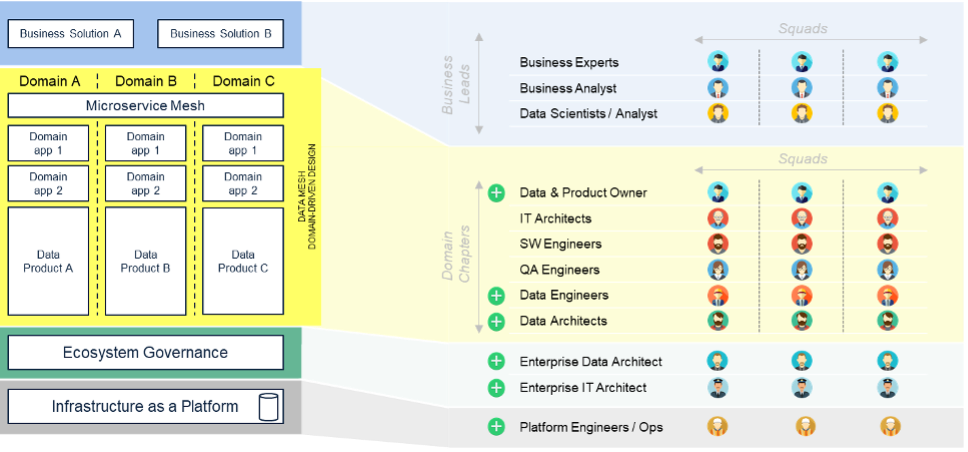
Il data mesh è quindi la composizione di tanti aspetti, in una possibile trasformazione del mondo dei dati verso un modello più agile e federale.
Bip xTech, il nostro Centro di Eccellenza nelle tecnologie esponenziali, può contare su esperti nelle tecnologie più avanzate nella gestione del dato, dal data engineering al cloud, dalla data governance alle architetture a microservizi, tutti ingredienti fondamentali per la transizione verso il data mesh.
Se sei interessato a saperne di più sulla nostra offerta o vuoi avere una conversazione con uno dei nostri esperti, invia un’e-mail a [email protected] con “Data Mesh” come oggetto, e sarai contattato prontamente.
[1] https://martinfowler.com/articles/data-monolith-to-mesh.html